What sort of data structures are you using within your kernel, and how do you avoid race conditions?
I'm doing the simple but inefficient method of disabling interrupts when my virtual allocate assigns a page or I wake up/sleep a thread. I don't want my timer interrupt grabbing control and potentially messing stuff up while I'm working on it. It works for now, but I it wouldn't work on a SMP setup.
How do you deal with race conditions?
I also use many message queues for communicating between different kernel threads. I use a linked list, but because my interrupt handlers are not synchronous, if it's called from a system call, I can't use a normal spinlock as it might leave the interrupt handler spinning. What kind of data structures do/would you use for this?
Data structures and race conditions used within kernels
-
AndrewAPrice

- Member

- Posts: 2300
- Joined: Mon Jun 05, 2006 11:00 pm
- Location: USA (and Australia)
Re: Data structures and race conditions used within kernels
In code that manipulates the thread queue, you must both disable interrupts and employ a spinlock, or use a method that doesn't require locking. Memory management, on the other hand, can use normal mutexes, as long as there is nothing in your mutex handling code that depends on the memory manager.
For message queues, I currently use ring buffers, which have an associated read mutex and a write mutex, and a read-ready and write-ready event. A caller can specify blocking or nonblocking mode. When data is sent from an interrupt, it must be the only writer, and nonblocking mode must be used, but it is okay to write even if a read is in progress. An event can optionally be signaled when data is available, so that a reader can monitor multiple message queues at once.
I am sure that it should be possible to manipulate a linked list in an interrupt safe manner. You may even be able to allow for multiple writers. Perhaps this link can give some ideas: http://www.liblfds.org/mediawiki/images ... d-Swap.pdf
For message queues, I currently use ring buffers, which have an associated read mutex and a write mutex, and a read-ready and write-ready event. A caller can specify blocking or nonblocking mode. When data is sent from an interrupt, it must be the only writer, and nonblocking mode must be used, but it is okay to write even if a read is in progress. An event can optionally be signaled when data is available, so that a reader can monitor multiple message queues at once.
I am sure that it should be possible to manipulate a linked list in an interrupt safe manner. You may even be able to allow for multiple writers. Perhaps this link can give some ideas: http://www.liblfds.org/mediawiki/images ... d-Swap.pdf
-
Combuster

- Member
- Posts: 9301
- Joined: Wed Oct 18, 2006 3:45 am
- Libera.chat IRC: [com]buster
- Location: On the balcony, where I can actually keep 1½m distance
- Contact:
Re: Data structures and race conditions used within kernels
Any true lock implies no interrupts in my case. This means that any pending locks are held by different cores and therefore always relinquish within a fixed amount of time - typically 10-20 instructions per contending core.
But most of the synchronisation does not happen in the kernel but rather via queueing - which operates lockless.
But most of the synchronisation does not happen in the kernel but rather via queueing - which operates lockless.
-
AndrewAPrice
- Member
- Posts: 2300
- Joined: Mon Jun 05, 2006 11:00 pm
- Location: USA (and Australia)
Re: Data structures and race conditions used within kernels
With my queues, I want to consumer to sleep and wait for messages, so I had to invent a system call - sleep_if_not_set(size_t address) and it sends the thread to sleep if the address at that memory location is not set.
However, the difficult part for me is that many of my interrupt handles (such as the keyboard and mouse handler) write to these queues, system calls like "open_file" send the VFS messages, etc, and I worry about sharing a mutex between a thread and an interrupt handler because if an interrupt handler locks a mutex locked by a thread I'll end up with a non-returning deadlock (for example - my Window Manager locks the queue to grab the top event, meanwhile the mouse moves and an interrupt fires, and the interrupt handler encounters the locked WM queue.)
My temporary solution right now is to temporarily disable interrupts when touching data structures that can also be touched by interrupts:
My interrupt handlers don't multitask, so I could put this code inside of two system calls - "Push to Queue" and "Pop from Queue" - which would make the operations atomic on a single core system, but this achieves the exact same effect as wrapping my pushing/popping in cli/sti but with the overhead of a system call.
It works for now, but it's going to break when I implement SMP, unless my kernel mutexes both disable interrupts and use spinlocks. All of this seems inefficient for a simple message queue data structure. Am I heading down the wrong path?
However, the difficult part for me is that many of my interrupt handles (such as the keyboard and mouse handler) write to these queues, system calls like "open_file" send the VFS messages, etc, and I worry about sharing a mutex between a thread and an interrupt handler because if an interrupt handler locks a mutex locked by a thread I'll end up with a non-returning deadlock (for example - my Window Manager locks the queue to grab the top event, meanwhile the mouse moves and an interrupt fires, and the interrupt handler encounters the locked WM queue.)
My temporary solution right now is to temporarily disable interrupts when touching data structures that can also be touched by interrupts:
Code: Select all
disable_interrupts();
/* read from queue */
enable_interrupts();
It works for now, but it's going to break when I implement SMP, unless my kernel mutexes both disable interrupts and use spinlocks. All of this seems inefficient for a simple message queue data structure. Am I heading down the wrong path?
My OS is Perception.
-
mathematician
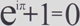
- Member

- Posts: 437
- Joined: Fri Dec 15, 2006 5:26 pm
- Location: Church Stretton Uk
Re: Data structures and race conditions used within kernels
For what it is worth, it seems to me that the scheduler should be kept informed when a lock is set or released. Then, if an interrupt fires, and it finds a lock set, it can make its needs known to the scheduler, and do an iret. Later on, when the lock is released, a process can be scheduled, or an internal handler called, to do whatever needs to be done on the interrupt handler's behalf.
I should say that these are just the thoughts I have had on the subject, and they have not yet been coded.
I should say that these are just the thoughts I have had on the subject, and they have not yet been coded.
The continuous image of a connected set is connected.
Re: Data structures and race conditions used within kernels
Hi,
The first type of spinlock acquires the lock; and also increases a "number of locks held" counter. Before doing a task switch the scheduler checks the "number of locks held" counter and if it's non-zero the scheduler sets a "task switch postponed" flag instead of doing the task switch. The code that releases the lock decreases the "number of locks held" counter, and if that counter becomes zero it checks the "task switch postponed" flag is set, and if it was set it calls the the scheduler to do the (postponed) task switch.
The second type of spinlock is the same, except it also disables IRQs.
The first type of spinlock is used as much as possible. However, any code that may be called from an IRQ handler can't use the first type of spinlock (as you end up with deadlocks - a CPU waiting to acquire a lock that won't be released until the same CPU returns from the IRQ handler). The second type of spinlock must be used for anything called from an IRQ handler.
Of course it's a micro-kernel and the only thing most IRQ handlers do is send messages; but sending messages may involve allocating memory (for message queues) so you end up with a significant part of the micro-kernel using the second type of spinlock.
For my next kernel; I'm planning to do things differently (mostly because I want "one kernel stack per CPU" instead of "one kernel stack per task", to improve memory consumption and cache locality). In this case; immediately after any switch from CPL=3 to CPL=0 the kernel will save the user-space task's state, and immediately before switching from CPL=0 back to CPL=3 it will decide which user-space task to switch to; and task switches won't happen anywhere else. This would mean that the "number of locks held" counter and "task switch postponed" flag won't be needed (and that I won't be able to have kernel threads, which is something I'll probably regret).
Cheers,
Brendan
I mostly have 2 types of spinlocks.MessiahAndrw wrote:How do you deal with race conditions?
The first type of spinlock acquires the lock; and also increases a "number of locks held" counter. Before doing a task switch the scheduler checks the "number of locks held" counter and if it's non-zero the scheduler sets a "task switch postponed" flag instead of doing the task switch. The code that releases the lock decreases the "number of locks held" counter, and if that counter becomes zero it checks the "task switch postponed" flag is set, and if it was set it calls the the scheduler to do the (postponed) task switch.
The second type of spinlock is the same, except it also disables IRQs.
The first type of spinlock is used as much as possible. However, any code that may be called from an IRQ handler can't use the first type of spinlock (as you end up with deadlocks - a CPU waiting to acquire a lock that won't be released until the same CPU returns from the IRQ handler). The second type of spinlock must be used for anything called from an IRQ handler.
Of course it's a micro-kernel and the only thing most IRQ handlers do is send messages; but sending messages may involve allocating memory (for message queues) so you end up with a significant part of the micro-kernel using the second type of spinlock.
For my next kernel; I'm planning to do things differently (mostly because I want "one kernel stack per CPU" instead of "one kernel stack per task", to improve memory consumption and cache locality). In this case; immediately after any switch from CPL=3 to CPL=0 the kernel will save the user-space task's state, and immediately before switching from CPL=0 back to CPL=3 it will decide which user-space task to switch to; and task switches won't happen anywhere else. This would mean that the "number of locks held" counter and "task switch postponed" flag won't be needed (and that I won't be able to have kernel threads, which is something I'll probably regret).
Cheers,
Brendan
For all things; perfection is, and will always remain, impossible to achieve in practice. However; by striving for perfection we create things that are as perfect as practically possible. Let the pursuit of perfection be our guide.

Re: Data structures and race conditions used within kernels
My approach to this sort of issue is quite simple: If at all possible, don't use shared data structures in interrupt handlers. IRQ handlers generally just set a "IRQ fired" flag which a thread is waiting on (my scheduler allows kernel threads to wait on arbitrary conditions) and the event is handled by the thread, not the interrupt handler.
There are a few exceptions to this; the scheduler, the system call handler and the page fault handler.
The scheduler gets around the issue by confirming that the relevant mutex is unclaimed before starting. If it's claimed, it simply returns to the running thread. This might mean that kernel threads that interact with the scheduler's data structures occasionally get a double time-slice, but I consider that acceptable. It also means that claiming the scheduler's mutex is the method that threads use to temporarily disable the scheduler for critical operations (critical as in that they may affect other threads, not time-critical, since IRQs can still fire). Disabling interrupts completely is rarely done, usually only in time-critical code in hardware drivers.
For the system call handler, we just re-enable interrupts and consider that the system call handler takes over from the calling thread. Since a thread executing userspace can't hold any kernel-space locks and can't modify kernel-space data, this is safe.
For the page fault handler, if the page fault is due to the use of memory-mapped I/O (which can be determined by examining the page table), shared data structures need to be read and the filesystem API called, etc. To handle this, I just consider that the page fault is a kind of system call and treat it the same way.
There are a few exceptions to this; the scheduler, the system call handler and the page fault handler.
The scheduler gets around the issue by confirming that the relevant mutex is unclaimed before starting. If it's claimed, it simply returns to the running thread. This might mean that kernel threads that interact with the scheduler's data structures occasionally get a double time-slice, but I consider that acceptable. It also means that claiming the scheduler's mutex is the method that threads use to temporarily disable the scheduler for critical operations (critical as in that they may affect other threads, not time-critical, since IRQs can still fire). Disabling interrupts completely is rarely done, usually only in time-critical code in hardware drivers.
For the system call handler, we just re-enable interrupts and consider that the system call handler takes over from the calling thread. Since a thread executing userspace can't hold any kernel-space locks and can't modify kernel-space data, this is safe.
For the page fault handler, if the page fault is due to the use of memory-mapped I/O (which can be determined by examining the page table), shared data structures need to be read and the filesystem API called, etc. To handle this, I just consider that the page fault is a kind of system call and treat it the same way.